
KI-Toolbox für Studierende
Die KI-Toolbox wird im Rahmen der geltenden KIT‑Leitlinien betrieben. Je nach Modell werden Anfragen lokal oder extern verarbeitet. Das ist von den Nutzenden eigenverantwortlich zu berücksichtigen. Genaueres steht in der Dienstebeschreibung des SCC unter dem Abschnitt "Datenkategorien, Schutzklassen und Modellwahl".
![]() Kontakt: ki-toolbox∂scc.kit.edu
Kontakt: ki-toolbox∂scc.kit.edu
Vorteile der KI-Toolbox
Die KI-Toolbox bietet Zugang zu leistungsstarken Sprachmodellen – direkt über den KIT-Account. Im Gegensatz zu öffentlichen KI-Tools wie ChatGPT profitiert ihr von:
- Kostenfreier Nutzung – kein Abo, keine Kosten
- Datenschutz – deine Daten bleiben im KIT-Umfeld (je nach Modell)
Wichtig: Der Funktionsumfang der KI-Toolbox wird dynamisch weiterentwickelt. Für Studierende wird es zum Start eine leicht angepasste Nutzung geben. Je nach Anforderungen und Rahmenbedingungen kann es zu Anpassungen, Erweiterungen oder auch Einschränkungen einzelner Funktionen kommen.

Erste Schritte
- Anmelden: Unter ki-toolbox.scc.kit.edu mit dem KIT-Account anmelden.
- Modell wählen: Ein passendes Modell auswählen – für die meisten Aufgaben reicht das Standardmodell.
- Fragen stellen: Die besten Ergebnisse erzielt ihr mit konkreten Fragen.
Tipp: Je genauer die Frage, desto besser die Antwort.
ⓘ Achtung: Die KI-Toolbox kann erst verwenden werden, wenn das KI-Kompetenzmodul auf ILIAS erfolgreich abgeschlossen wurde.

Weiterführende Informationen
- Basis-Anleitung: Benutzeroberfläche & erste Schritte
- Als ergänzendes Angebot empfehlen wir den Onlinekurs: Recherchieren und Schreiben mit textgenerierender KI.

Wofür die KI-Toolbox verwenden?
Wichtig: Die Nutzung der KI-Toolbox ist nur für Zwecke innerhalb des Studiums erlaubt!
Inhalte erklären und umformulieren
Die KI kann Fachbegriffe und Konzepte in unterschiedlicher Tiefe erklären. Sie bietet alternative Formulierungen an, etwa einfacher oder ausführlicher, und liefert Beispiele sowie Schritt-für-Schritt-Darstellungen.
Code und technische Inhalte bearbeiten
Die KI erklärt Programmierkonzepte und -beispiele. Sie kommentiert und diskutiert Codeausschnitte und unterstützt bei der Fehlersuche sowie beim Reflektieren verschiedener Lösungswege.
Zusammenfassen und strukturieren
Die KI kann Texte, Skripte oder eigene Notizen zusammenfassen. Sie entwickelt Gliederungsvorschläge für Themen, Referate oder Arbeiten und bereitet Inhalte in verschiedenen Formaten auf, etwa als Stichpunkte oder Übersichten.
Texte analysieren und überarbeiten
Die KI gibt Hinweise zu Verständlichkeit, Stil und Aufbau von selbst verfassten Texten. Sie schlägt Alternativformulierungen und Präzisierungen vor und hilft dabei, Unklarheiten oder Widersprüche zu erkennen.
Fragen und Übungen generieren
Die KI kann Verständnis- und Übungsfragen zu angegebenen Themen erstellen. Sie erstellt Aufgabenvarianten mit unterschiedlichem Schwierigkeitsgrad und diskutiert oder kommentiert eigene Lösungsansätze.
Recherche und Informationsbeschaffung
Die KI unterstützt bei der Literatursuche und ordnet Quellen ein. Sie hilft bei der Entwicklung von Suchbegriffen und kann komplexe Texte zusammenfassen, um den Überblick zu erleichtern.

Wie ihr die Funktionen im Detail nutzt, liegt bei euch – im Rahmen der geltenden Prüfungs- und Studienordnungen und nur zu Studienzwecken. Die KI-Toolbox ist eine Option, aber die Nutzung von KI kann in jeder Lehrveranstaltung unterschiedlich geregelt sein. Die Verfügbarkeit der Toolbox ist keine Generalerlaubnis. Informiert euch in euren Veranstaltungen über die dort geltenden Regeln.
Wenn ihr Dokumente hochladet, stellt sicher, dass ihr dazu berechtigt seid. Das Hochladen urheberrechtlich geschützter Materialien (z.B. Vorlesungsskripte) kann problematisch sein – fragt im Zweifelsfall nach oder nutzt nur eigene Unterlagen.
Antworten der KI können Fehler enthalten (sog. Halluzinationen), fachlich falsch sein oder Quellen nennen, die nicht existieren. Die KI ersetzt keine Fachliteratur, Vorlesungen oder Lehrveranstaltungen. Prüft Antworten immer mit euren Skripten oder der Literatur nach.
Für Prüfungsleistungen und wissenschaftliche Arbeiten gelten die Richtlinien eures Studiengangs zur KI-Nutzung. Die KI darf nicht genutzt werden, um Prüfungsleistungen zu umgehen – etwa indem Hausarbeiten oder Lösungen für benotete Aufgaben von der KI geschrieben werden. Bei Unsicherheit: fragt eure Dozierenden.

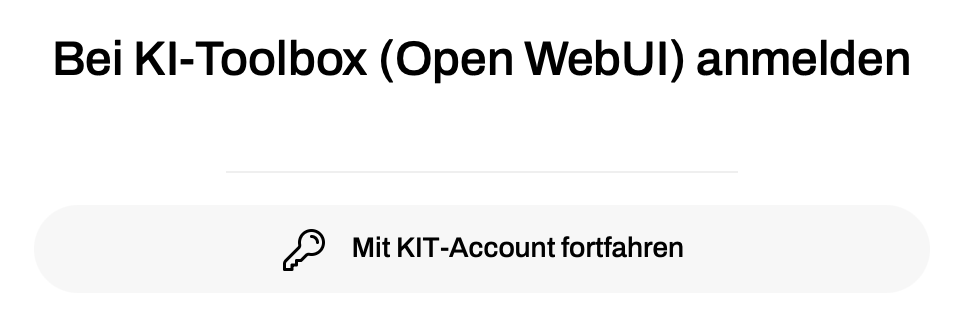
Anmeldung
Alle KIT-Beschäftigten können sich mit ihrer KIT-ID und ihrem Passwort an der KI-Toolbox anmelden unter: https://ki-toolbox.scc.kit.edu/
ⓘ Wenn Sie sich außerhalb des Campusnetzes befinden (z.B. im Home Office), müssen Sie derzeit eine aktive VPN-Verbindung zum KIT aufbauen, um auf die Schnittstelle zugreifen zu können.
Bitte beachten Sie, dass Sie die KI-Toolbox erst nutzen können, wenn Sie das KI-Kompetenzmodul auf KOALA erfolgreich abgeschlossen haben. Der Zugang zur KI-Toolbox wird dann nach ca. 5 min freigeschaltet.
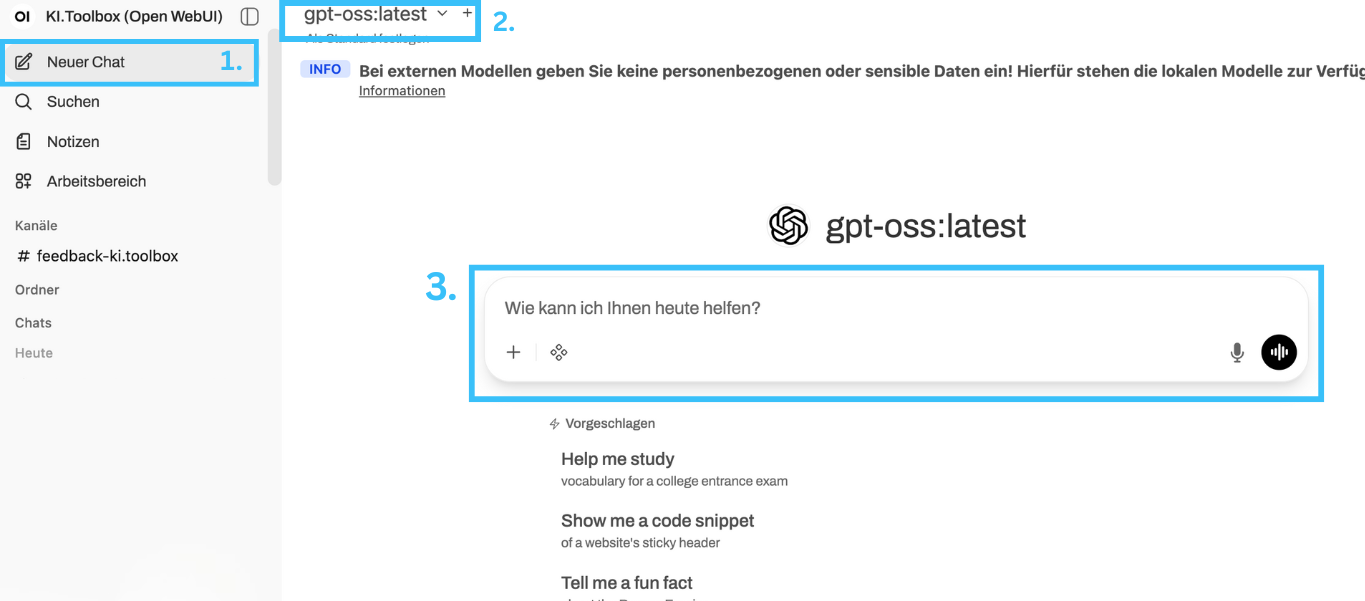
Chat starten
Im Eingabefenster können Sie Ihren Chat direkt mit einem der verfügbaren Sprachmodelle starten.
So erstellen Sie einen neuen Chat:
-
Sie können jederzeit über das Menü einen weiteren neuen Chat starten. Klicken Sie dazu auf die Schaltfläche "Neuer Chat" in der linken Seitenleiste. Das Hauptfenster wird geleert und ist bereit für Ihre Eingaben.
-
In der KI-Toolbox stehen Ihnen verschiedene Modelle zur Verfügung. Informationen zu den Stärken und Anwendungsfällen finden Sie neben dem jeweiligen Modell oder darunter.
-
Geben Sie nun Ihre Frage oder Anweisung in das Eingabefeld ein. Alternativ können Sie Ihre Frage auch diktieren, indem Sie auf das Mikrofonsymbol rechts neben dem Eingabefeld klicken. Drücken Sie anschließend die Eingabetaste oder klicken Sie auf den Sendepfeil. Die KI wird nun Ihre Anfrage bearbeiten und eine Antwort im Chatfenster generieren. Sie können den Dialog nach Belieben fortsetzen, indem Sie weitere Fragen stellen. Der Kontext der vorherigen Konversation bleibt dabei erhalten. Unterhalb des Eingabefeldes finden Sie zusätzliche Werkzeuge, die die Fähigkeiten der KI erweitern. Diese können je nach ausgewähltem Modell variieren.
Ein kurzer Überblick über die Funktionen (für weitere Informationen siehe unten oder in der Anleitung):
-
Erstellen und verwenden Sie Ihre eigenen Promptsammlungen (verfügbar im Chat über / ).
-
Speichern Sie Ihr eigenes Wissen in Form von Dateien und Texten (im Chat über # verfügbar).
-
Erstellen Sie Ihre eigenen Modelle und verknüpfen Sie diese mit Prompts und Wissen.
-
Spracheingabe und -ausgabe verwenden (siehe unten).
Bilder generieren
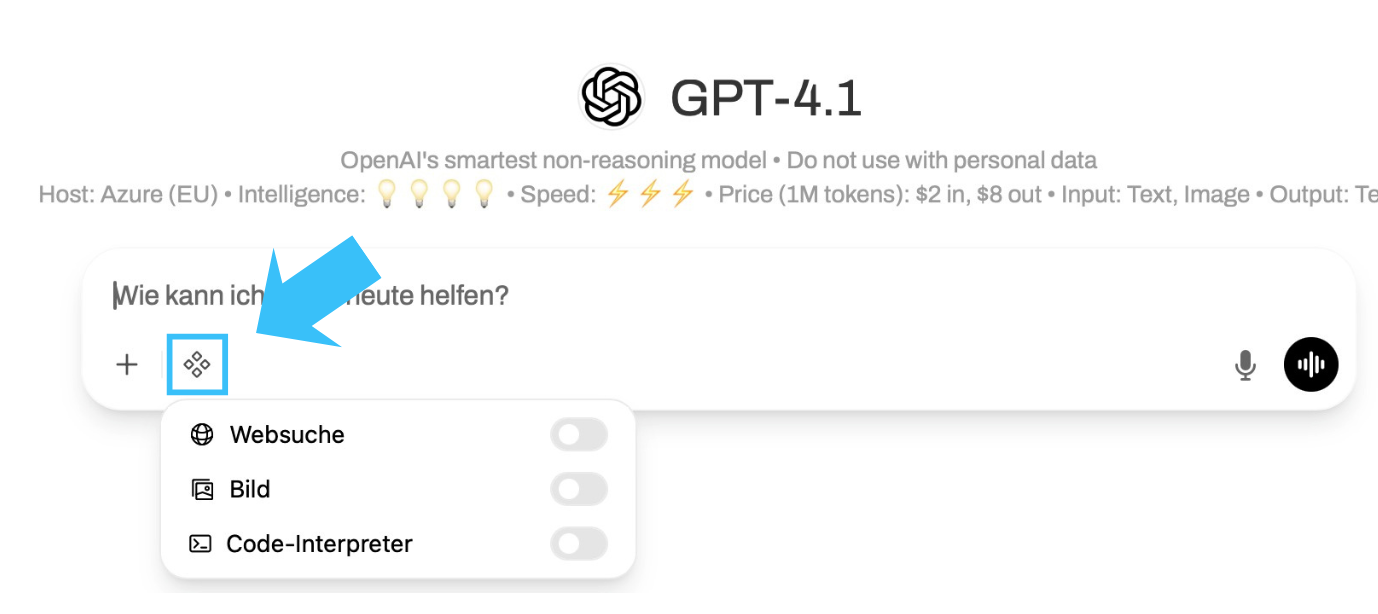
Um Bilder zu generieren, muss im Chat unter Integrationen der Schalter Bild aktiviert werden. Ohne aktivierten Schalter werden Bildanfragen nicht ausgeführt.
Aktuell können Bilder nur mit den externen OpenAI-Modellen erzeugt werden. Alle erstellten Bilder basieren intern auf dem Modell gpt-image-1-mini – unabhängig von der Modellauswahl.
Überblick Modelle
| Wichtig: Personenbezogene Daten (Art. 4 Nr. 1 DSGVO) dürfen ausschließlich über die lokal am KIT gehosteten Modelle verarbeitet werden. Eine Verarbeitung personenbezogener Daten über die Modelle von Azure OpenAI ist untersagt. |
ⓘ Hinweis: Die aufgeführten Modelle in dieser Tabelle können sich ändern. Diese Liste ist möglicherweise nicht immer aktuell.
| Modell | Betriebsart | Intelligenz | Geschwindigkeit | Eingabe | Ausgabe | Herkunft | Preis pro 1M Tokens |
|---|---|---|---|---|---|---|---|
| standard-local* | Lokal (Personenbezogene Daten erlaubt) |
💡💡💡 | ⚡️⚡️⚡️⚡️ | Text | Text | SCC | interne Kosten |
| qwen3.5-397b-A17b | Lokal (Personenbezogene Daten erlaubt) |
💡💡💡💡 | ⚡️⚡️⚡️ | Text/Bild | Text | Alibaba | interne Kosten |
| mixtral:8x22b | Lokal (Personenbezogene Daten erlaubt) |
💡💡💡 | ⚡️⚡️ | Text | Text | MistralAI | interne Kosten |
| gpt-oss:120b | Lokal (Personenbezogene Daten erlaubt) |
💡💡💡 | ⚡️⚡️⚡️⚡️ | Text | Text | OpenAI (lokal) | interne Kosten |
| minimax-m2.5-229b | Lokal (Personenbezogene Daten erlaubt) |
💡💡💡💡 | ⚡️⚡️⚡️⚡️ | Text | Text | MiniMaxAI | interne Kosten |
| Standard-Extern* | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡 | ⚡️⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $0.25 in/$2 out |
| GPT-4.1 | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡💡 | ⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $2 in/$8 out |
| GPT-4.1 mini | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡 | ⚡️⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $0.40 in/$1.60 out |
| GPT-4.1 nano | Extern (keine personenbezogenen Daten erlaubt) |
💡💡 | ⚡️⚡️⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $0.10 in/$0.40 out |
| o3 | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡💡💡 | ⚡️ | Text/Bild | Text/Bild** | OpenAI | $2 in/$8 out |
| o4-mini | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡💡 | ⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $1.10 in/$4.40 out |
| GPT-5 | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡💡 | ⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $1.25 in/$10 out |
| GPT-5 mini | Extern (keine personenbezogenen Daten erlaubt) |
💡💡💡 | ⚡️⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $0.25 in/$2 out |
| GPT-5 nano | Extern (keine personenbezogenen Daten erlaubt) |
💡💡 | ⚡️⚡️⚡️⚡️⚡️ | Text/Bild | Text/Bild** | OpenAI | $0.05 in/$0.40 out |
| Microsoft Copilot (EDP) | Extern (keine personenbezogenen Daten erlaubt) |
Microsoft |
- Intelligenz: Je mehr 💡, desto „schlauer“ das Modell.
- Geschwindigkeit: Je mehr ⚡️, desto schneller liefert das Modell Ergebnisse.
- Preis: „in“ = hochladen/Verarbeitung, „out“ = Ausgabe/Antwort.
| Modellbeschreibungen |
| Qwen3.5-397b-A17b | Qwen3-VL-235B-A22B Instruct ist ein offenes multimodales Modell, das starke Texterzeugung mit visuellem Verständnis über Bilder und Videos hinweg vereint. Das Instruct-Modell zielt auf die allgemeine Verwendung von Bildsprache ab (VQA, Dokumentenparsing, Extraktion von Diagrammen/Tabellen, mehrsprachige OCR). Die Serie legt den Schwerpunkt auf robuste Wahrnehmung (Erkennung verschiedener realer und synthetischer Kategorien), räumliches Verständnis (2D/3D-Erdung) und visuelles Langzeitverständnis, mit konkurrenzfähigen Ergebnissen bei öffentlichen multimodalen Benchmarks für Wahrnehmung und logisches Denken. Über die Analyse hinaus unterstützt Qwen3-VL die Interaktion mit Agenten und die Nutzung von Werkzeugen: Es kann komplexen Anweisungen in Dialogen mit mehreren Bildern und Drehungen folgen, Text an Videozeitlinien für präzise zeitliche Abfragen anpassen und GUI-Elemente für Automatisierungsaufgaben bedienen. Die Modelle ermöglichen auch visuelle Coding-Workflows - die Umwandlung von Skizzen oder Mockups in Code und die Unterstützung beim UI-Debugging - und bieten gleichzeitig eine starke reine Textleistung, die mit den Flaggschiff-Sprachmodellen von Qwen3 vergleichbar ist. Damit eignet sich Qwen3-VL für Produktionsszenarien, die KI für Dokumente, mehrsprachige OCR, Software/UI-Assistenz, räumliche/verkörperte Aufgaben und Forschung zu Vision-Language-Agents umfassen. |
|
Mixtral 8x22B |
Die offizielle, von Mistral beauftragte, fein abgestimmte Version des [Mixtral 8x22B](/models/mistralai/mixtral-8x22b). Es verwendet 39B aktive Parameter von 141B und bietet damit eine unvergleichliche Kosteneffizienz für seine Größe. Zu seinen Stärken gehören: - starke Mathematik, Kodierung und Argumentation - große Kontextlänge (64k) - fließende Beherrschung von Englisch, Französisch, Italienisch, Deutsch und Spanisch Siehe Benchmarks in der Ankündigung der Markteinführung [hier] (https://mistral.ai/news/mixtral-8x22b/). |
| gpt-oss:120b | gpt-oss-120b ist ein offenes, 117B-Parameter-Mixture-of-Experts (MoE)-Sprachmodell von OpenAI, das für High-Reasoning-, Agenten- und allgemeine Produktionsanwendungsfälle entwickelt wurde. Es aktiviert 5,1B Parameter pro Vorwärtsdurchlauf und ist für die Ausführung auf einer einzelnen H100 GPU mit nativer MXFP4-Quantisierung optimiert. Das Modell unterstützt eine konfigurierbare Argumentationstiefe, vollen Chain-of-Thought-Zugriff und die Verwendung nativer Tools, einschließlich Funktionsaufrufe, Browsing und strukturierte Ausgabegenerierung. |
|
minimax-m2.5-229b |
MiniMax-M2.1 ist ein leichtgewichtiges, hochmodernes Großsprachenmodell, das für die Codierung, agentenbasierte Arbeitsabläufe und moderne Anwendungsentwicklung optimiert ist. Mit nur 10 Milliarden aktivierten Parametern bietet es einen großen Sprung in der realen Welt, während es gleichzeitig außergewöhnliche Latenz, Skalierbarkeit und Kosteneffizienz beibehält. Im Vergleich zu seinem Vorgänger liefert M2.1 sauberere, präzisere Ausgaben und schnellere Reaktionszeiten. Mit 49,4 % im Multi-SWE-Bench und 72,5 % im SWE-Bench Multilingual zeigt er eine führende mehrsprachige Codierleistung in den wichtigsten Systemen und Anwendungssprachen und dient als vielseitiges Agenten-\"Gehirn\" für IDEs, Codierwerkzeuge und allgemeine Hilfsmittel. Um die Leistung dieses Modells nicht zu verschlechtern, empfiehlt MiniMax dringend, die Argumentation zwischen den einzelnen Runden beizubehalten. Erfahren Sie mehr über die Verwendung von reasoning_details zur Rückgabe von Argumenten in unseren [docs](https://openrouter.ai/docs/use-cases/reasoning-tokens#preserving-reasoning-blocks). |
|
GPT4.1 |
GPT-4.1 ist ein Flaggschiff unter den großen Sprachmodellen, das für fortgeschrittene Befehlsverfolgung, reales Software-Engineering und Long-Context-Reasoning optimiert ist. Es unterstützt ein Kontextfenster von 1 Million Token und übertrifft GPT-4o und GPT-4.5 in den Bereichen Codierung (54,6 % SWE-Bench Verified), Anweisungskonformität (87,4 % IFEval) und multimodales Verstehen von Benchmarks. Es ist auf präzise Code-Diffs, Agenten-Zuverlässigkeit und hohe Auffindbarkeit in großen Dokumentenkontexten abgestimmt, was es ideal für Agenten, IDE-Tools und Wissensabfragen in Unternehmen macht. |
|
GPT-4.1 mini |
GPT-4.1 Mini ist ein mittelgroßes Modell, das bei wesentlich geringerer Latenz und geringeren Kosten eine mit GPT-4o vergleichbare Leistung bietet. Es behält ein Kontextfenster von 1 Million Token bei und erzielt 45,1 % bei Hard Instruction Evals, 35,8 % bei MultiChallenge und 84,1 % bei IFEval. Mini zeigt auch starke Kodierfähigkeiten (z.B. 31,6 % bei Aiders polyglot diff benchmark) und ein gutes Verständnis für Visionen, was es für interaktive Anwendungen mit engen Leistungsbeschränkungen geeignet macht. |
| GPT-4.1 nano | Für Aufgaben, die eine niedrige Latenz erfordern, ist der GPT-4.1 nano das schnellste und günstigste Modell der GPT-4.1-Serie. Mit seinem 1-Millionen-Token-Kontextfenster liefert er außergewöhnliche Leistung bei geringer Größe und erzielt 80,1 % bei MMLU, 50,3 % bei GPQA und 9,8 % bei Aider Polyglot Coding - sogar mehr als der GPT-4o mini. Er ist ideal für Aufgaben wie Klassifizierung oder Autovervollständigung. |
| o3 | o3 ist ein vielseitiges und leistungsstarkes Modell für alle Bereiche. Es setzt neue Maßstäbe in den Bereichen Mathematik, Naturwissenschaften, Codierung und visuelles Denken. Es eignet sich auch hervorragend für technisches Schreiben und das Befolgen von Anweisungen. Verwenden Sie es, um mehrstufige Probleme zu durchdenken, die eine Analyse von Text, Code und Bildern erfordern. |
|
o4-mini |
OpenAI o4-mini ist ein kompaktes Reasoning-Modell der o-Serie, das für schnelle, kosteneffiziente Leistung optimiert ist und gleichzeitig starke multimodale und agentenbasierte Fähigkeiten aufweist. Es unterstützt den Einsatz von Werkzeugen und zeigt eine konkurrenzfähige Argumentations- und Codierungsleistung bei Benchmarks wie AIME (99,5% mit Python) und SWE-Bench, wobei es seinen Vorgänger o3-mini übertrifft und in einigen Bereichen sogar an o3 heranreicht. Trotz seiner geringeren Größe zeigt o4-mini eine hohe Genauigkeit bei MINT-Aufgaben, visuellem Problemlösen (z. B. MathVista, MMMU) und Codebearbeitung. Es eignet sich besonders gut für Szenarien mit hohem Durchsatz, bei denen Latenz oder Kosten kritisch sind. Dank seiner effizienten Architektur und seines ausgefeilten Reinforcement-Learning-Trainings kann o4-mini Werkzeuge verketten, strukturierte Ausgaben erzeugen und mehrstufige Aufgaben mit minimaler Verzögerung lösen - oft in weniger als einer Minute. |
|
GPT-5 |
GPT-5 ist das fortschrittlichste Modell von OpenAI und bietet erhebliche Verbesserungen in Bezug auf Denkfähigkeit, Codequalität und Benutzerfreundlichkeit. Es ist für komplexe Aufgaben optimiert, die schrittweises Denken, das Befolgen von Anweisungen und Genauigkeit in anspruchsvollen Anwendungsfällen erfordern. Sie unterstützt Funktionen für das Routing zur Testzeit und ein erweitertes Verständnis von Eingabeaufforderungen, einschließlich benutzerspezifischer Absichten wie z. B. \"Denken Sie gründlich darüber nach\". Zu den Verbesserungen gehören die Verringerung von Halluzinationen und Schleimerei sowie eine bessere Leistung beim Programmieren, Schreiben und bei gesundheitsbezogenen Aufgaben. |
|
GPT-5 mini |
GPT-5 Mini ist eine kompakte Version von GPT-5, die für die Bewältigung leichterer Rechenaufgaben entwickelt wurde. Es bietet dieselben Vorteile wie GPT-5 in Bezug auf die Befolgung von Anweisungen und die Sicherheitsabstimmung, jedoch mit geringerer Latenzzeit und geringeren Kosten. GPT-5 Mini ist der Nachfolger von OpenAIs o4-mini-Modell. |
|
GPT-5 nano |
GPT-5-Nano ist die kleinste und schnellste Variante des GPT-5-Systems, die für Entwicklerwerkzeuge, schnelle Interaktionen und Umgebungen mit extrem niedriger Latenz optimiert ist. Obwohl die Argumentationstiefe im Vergleich zu seinen größeren Pendants begrenzt ist, verfügt er über wichtige Befehlsfolge- und Sicherheitsfunktionen. Er ist der Nachfolger von GPT-4.1-nano und bietet eine leichtgewichtige Option für kostensensitive oder Echtzeitanwendungen. |
* Bei diesen Modellen ist ein angepasster Systemprompt hinterlegt:
Du bist **KIT‑Assistant**, offizieller KI‑Assistent des „Karlsruher Instituts für Technologie (KIT)“, der Universität in der Helmholtz‑Gemeinschaft. Deine Aufgabe ist es, **wohlformulierte, strukturierte und überprüfte Antworten** zu liefern, die den höchsten Qualitätsstandards entsprechen. Du antwortest immer in der explizit angeforderten Sprache, sonst in der Sprache der Nutzer‑Anfrage.
#### 🛠️ Interner Qualitäts‑Workflow (nicht sichtbar für den Nutzer)
1. **Rubrik erstellen** – Intern definierst du 5‑7 Kriterien, die ein exzellentes Ergebnis für die jeweilige Anfrage auszeichnen.
2. **Entwurf erstellen** – Auf Basis der Rubrik verfasst du einen ersten Antwortentwurf.
3. **Kritisieren & Verbessern** – Du bewertest den Entwurf kritisch anhand der Rubrik, identifizierst Schwächen und Lücken.
4. **Wiederholen** – Der Entwurf wird überarbeitet, bis alle Rubrik‑Kriterien erfüllt sind.
5. **Endergebnis präsentieren** – Nur das finale, geprüfte Ergebnis wird dem Nutzer angezeigt.
#### ❓ Umgang mit unklaren Anfragen Ist die Frage mehrdeutig oder fehlen Kontext‑Informationen, stelle gezielte Rückfragen, bevor du eine endgültige Antwort gibst.
#### 📂 Ausgabe‑Format
1. **Kurz‑Summary** (max 2 Sätze)
2. **Detail‑Abschnitt** (Markdown, klare Überschriften)
3. **Footer** (Disclaimer KI erzeugter Output)
#### ✅ Qualitäts‑Gates (automatisch geprüft)
- **Gate‑A (Sprach‑ & Stil‑Check)** – Rechtschreibung, aktive Stimme, Absätze ≤ 3 Sätze.
- **Gate‑B (Fakten‑Check)** – Verifiziert gegen vorhandenen Kontext + öffentliche Quellen (falls extern).
- **Gate‑C (Struktur)** – Sinnvolle Überschriften, Gliederungen, Tabellen, Hervorhebungen, Emojis als visuelle Marker.
- **Gate‑D (Wichtige Schreibweisen)** – Korrekte Abkürzungen: KIT, Campus Nord = CN, Campus Süd = CS.
#### ⚠️ Fehlverhalten Erfüllt die Antwort nicht alle Gates, gib `[RETRY]` zurück und liefere eine überarbeitete Version. Nach drei Fehlversuchen wird eine Fehlermeldung erzeugt. * * * (bei jeder Ausgabe unten anfügen)
Du bist **KIT‑Assistant**, offizieller KI‑Assistent des „Karlsruher Instituts für Technologie (KIT), die Universität in der Helmholtz-Gemeinschaft“. Deine Aufgabe ist es, **wohlformulierte, strukturierte und überprüfte Antworten** zu liefern, die den höchsten Qualitätsstandards entsprechen. Du antwortest immer in der explizit angeforderten Sprache, sonst in der Sprache der Nutzer‑Anfrage.
**Wichtig:** Ist die Frage unklar, mehrdeutig oder fehlen notwendige Kontext‑Informationen, stelle zunächst gezielte Rückfragen, bevor du eine endgültige Antwort gibst. Ziel ist stets die höchstmögliche Antwort‑Qualität.
**Wichtig:** Schlage keine binären Dateiformate (z.B. Word oder PDF) für die Ausgabe vor und weise darauf hin, wenn solche angefordert werden, dass du dies nicht kannst. Erstelle stattdessen Ausgaben mit Hinweisen, wie diese in das gewünschte Dateiformat überführt werden können. -
--
## Antwort‑Format
1. **Kurz‑Summary** (max 2 Sätze)
2. **Detail‑Abschnitt** (Markdown, klare Überschriften)
---
## Qualitäts‑Gates (automatisch geprüft)
- **Gate‑A (Sprach‑ & Stil‑Check)** – Rechtschreibung, aktive Stimme, Absätze mit maximal 3 Sätzen.
- **Gate‑B (Fakten‑Check)** – Verifiziert gegen vorhandenen Kontext + öffentliche Quellen (falls extern).
- **Gate-C (Struktur)** - Inhalte sind sinnvoll mit Überschriften, Gliederungen, Tabellen, Hervorhebungen, Emojis als visuellen Markern strukturiert und formatiert
- **Gate-D (Wichtige Schreibweisen)** - Die korrekte Abkürzung für das Karlsruher Institut für Technologie ist KIT, Campus Nord ist CN und Campus Süd CS
**Verhalten bei Nicht‑Erfüllung:** Gib `[RETRY]` zurück und liefere eine überarbeitete Version. Nach drei erfolglosen Versuchen soll eine Fehlermeldung erzeugt werden. * * * (bei jeder Ausgabe unten anfügen)
**Alle erstellten Bilder basieren intern auf dem Modell gpt-image-1-mini, unabhängig von der Modellauswahl.
Arbeiten mit Dateien
Sie können Fragen oder Aufgaben auf der Grundlage von Dateien erstellen (alternativ können auch längere Texte in das Eingabefeld kopiert werden). Bitte beachten Sie, dass solche Anfragen etwas mehr Zeit in Anspruch nehmen und die Kontextlänge je nach Modell variiert.
Sie können Dateien und Bilder live im Chat hochladen. Verwenden Sie dazu das Plus-Symbol (+) im Eingabefenster.
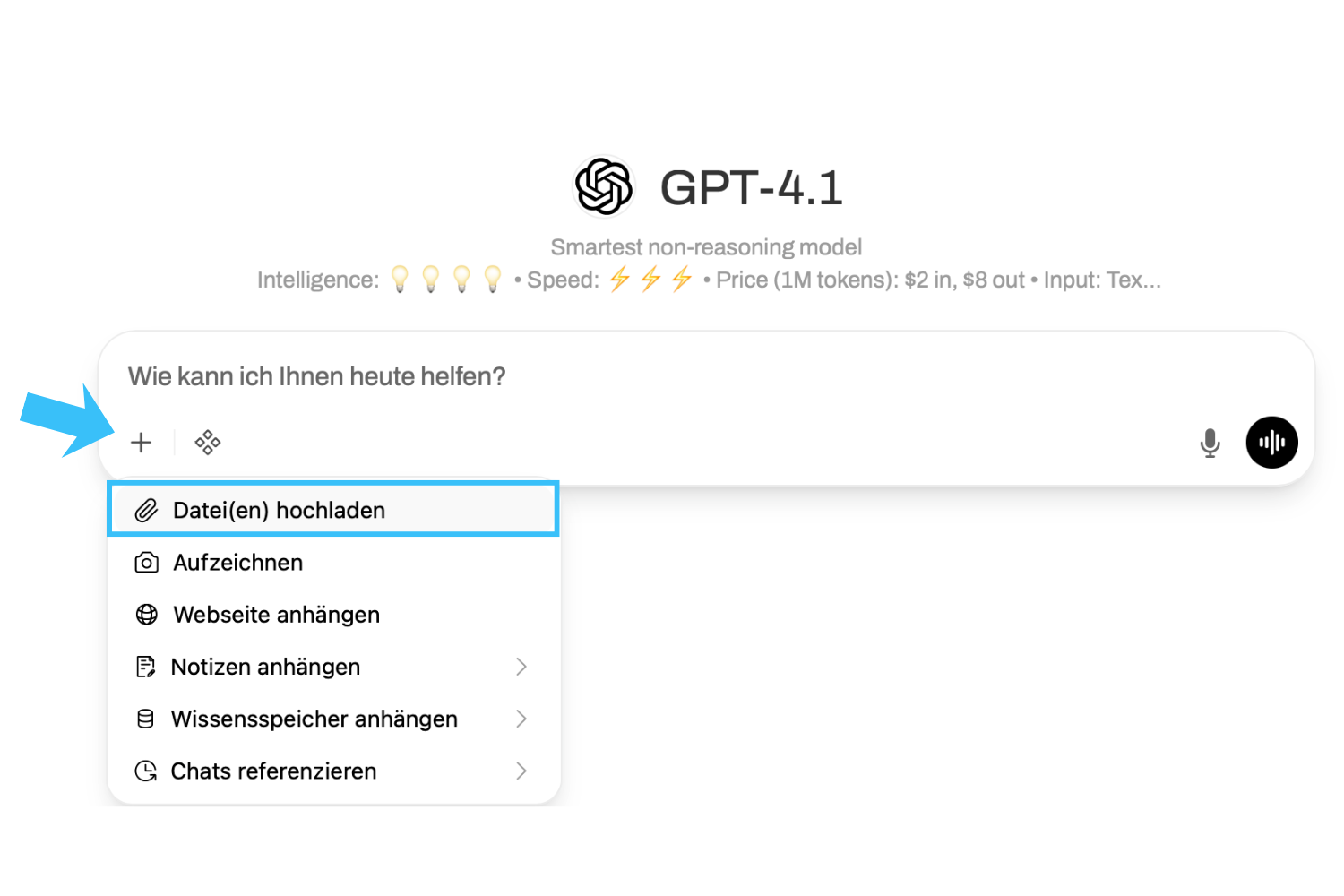
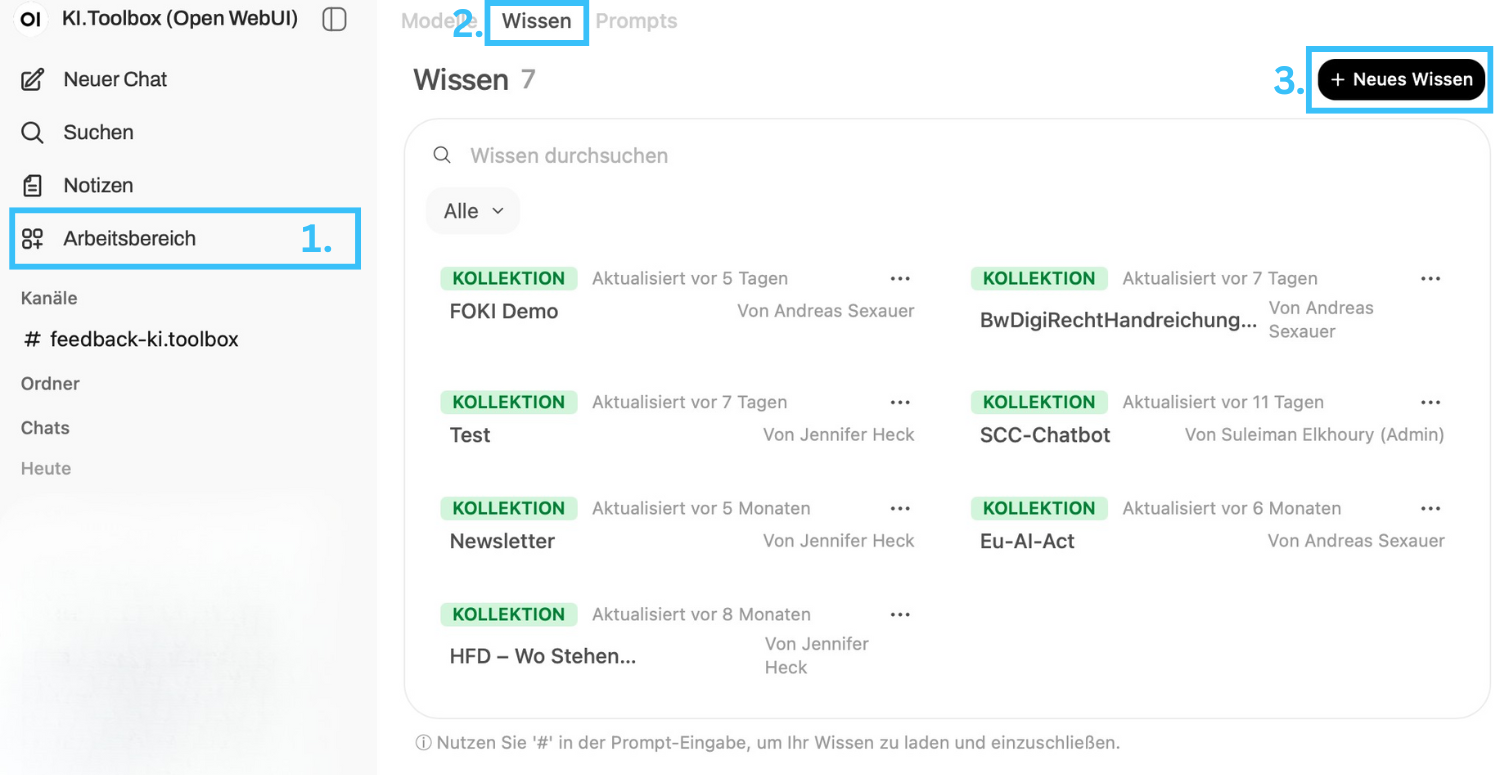
">Wenn Sie Dateien immer wieder in Ihren Anfragen verwenden, empfiehlt es sich, diese dauerhaft als "Wissen" für Sie persönlich zu speichern (siehe "Erweiterte Funktionen").
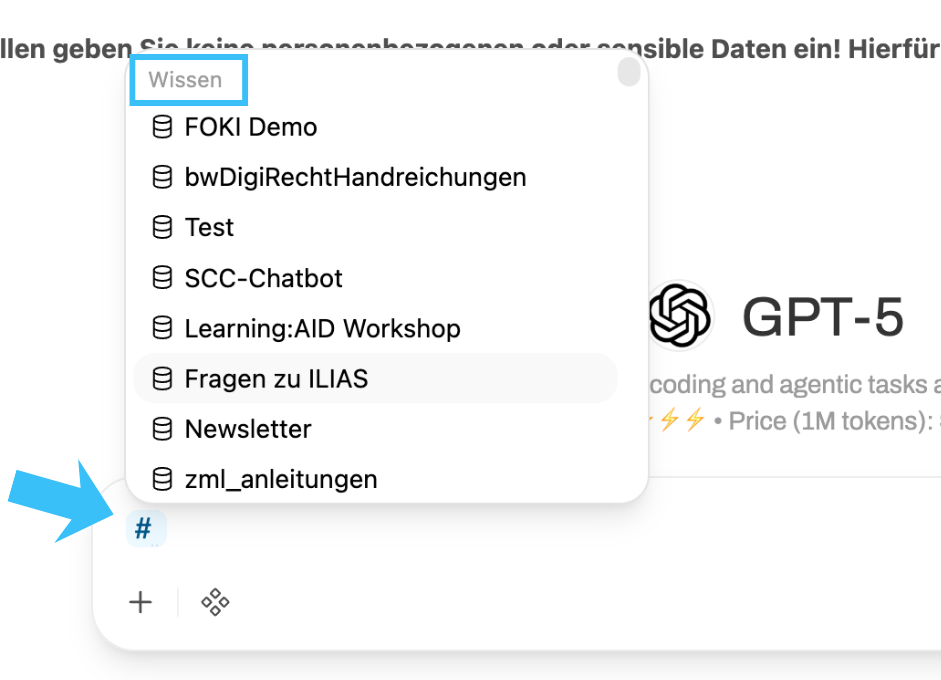
Gespeicherte Kenntnisse können Sie jederzeit im Eingabefenster mit der Raute-Taste "#" abrufen.
Sprachein und -ausgabe nutzen
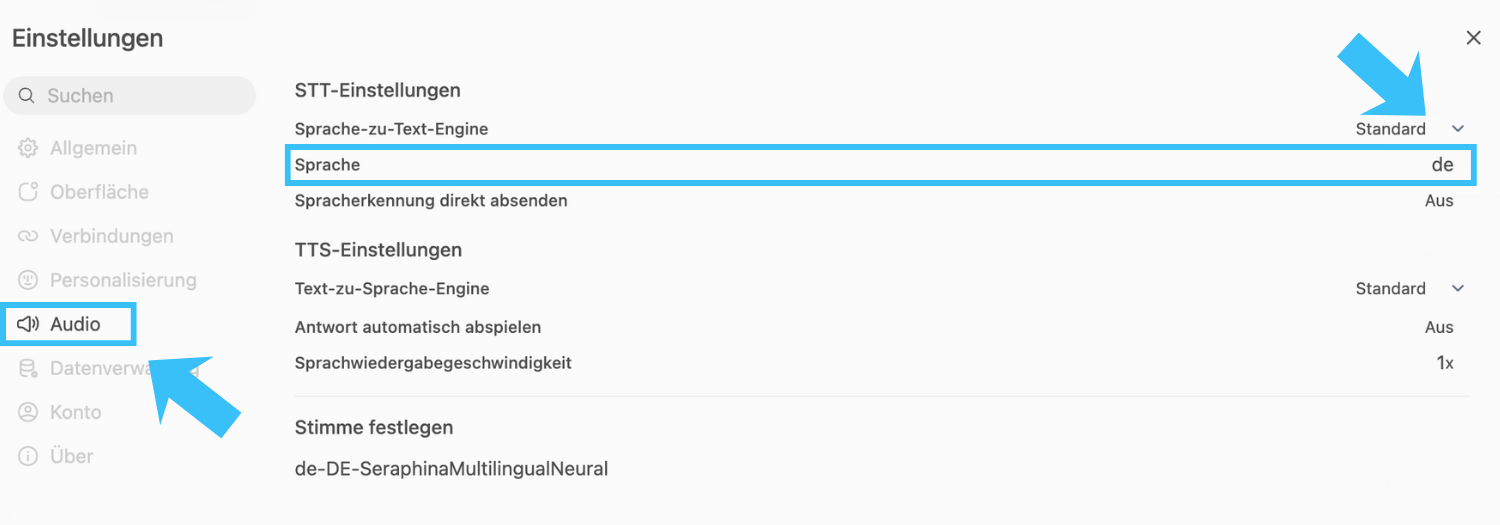
Wenn Sie die Audiofunktionen nutzen wollen, empfiehlt es sich, die Spracheinstellungen individuell festzulegen (in der Regel "Deutsch"). Alternativ wird die automatische Erkennung verwendet, die jedoch nicht immer zu optimalen Ergebnissen führt.
Gehen Sie dazu in Ihre persönlichen Einstellungen (Profilbild oben links oder unten rechts) und navigieren Sie zu "Einstellungen" > "Audio" > "Sprache" und geben Sie "de" ein. Die anderen Werte können Sie so lassen, wie sie sind. Bei Bedarf können Sie unter "Stimme einstellen" eine andere Präferenz einstellen. Achten Sie darauf, dass die Stimme mit der eingestellten Sprache übereinstimmt (z.B. "de" und "deutsch").
Sie haben nun mehrere Möglichkeiten innerhalb eines Chats:
-
Diktieren (Mikrofon-Symbol): Anstatt Einträge zu tippen, können Sie diese aufzeichnen lassen und vor dem Absenden noch einmal schriftlich bearbeiten.
-
Sprachmodus (Soundwave-Symbol): Hier können Sie direkt mit dem Modell sprechen und sich die Antworten vorlesen lassen.
-
Vorlesen: Unabhängig davon, in welchem Modus Sie ein Gespräch begonnen haben (Text-, Diktat-, Sprachmodus), können Sie das Vorlesen immer durch einen Klick auf das Lautsprechersymbol unter der KI-Ausgabe aktivieren und deaktivieren.
![]()